 |
|
You are here: Foswiki>Cosmo Web>RadioT4>RadioT4TimingTenMs (18 Nov 2010, BoudRoukema)Edit Attach
<< Cosmo
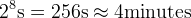 , maxpoll 10 (debian/etch default) means about 16 minutes max polling interval. Two plots of the same data - offsets from the server which at that moment is chosen as the synchronisation server - with different vertical scales:
, maxpoll 10 (debian/etch default) means about 16 minutes max polling interval. Two plots of the same data - offsets from the server which at that moment is chosen as the synchronisation server - with different vertical scales:
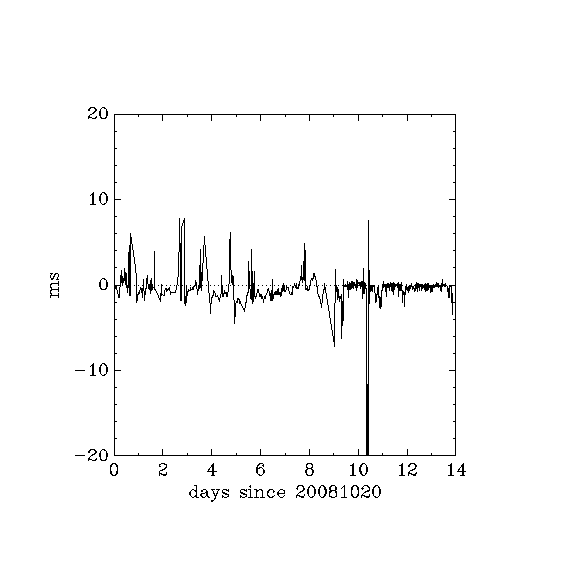
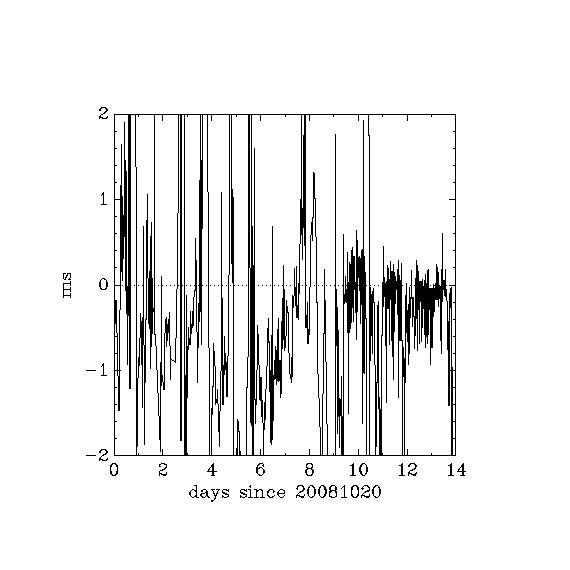 At each polling interval, several servers are contacted. A complex algorithm is used to choose among these and decide which server is most reliable/precise. In practice, the chosen server can remain stable for many hours or days.
Statistics of these offsets in units of 300 km (a.k.a. 1 ms):
At each polling interval, several servers are contacted. A complex algorithm is used to choose among these and decide which server is most reliable/precise. In practice, the chosen server can remain stable for many hours or days.
Statistics of these offsets in units of 300 km (a.k.a. 1 ms):
The third line excludes the 2.4 hour spike from 10.32 days to 10.42 days.
The largest offset during the 2.4h spike was -21.5 ms.
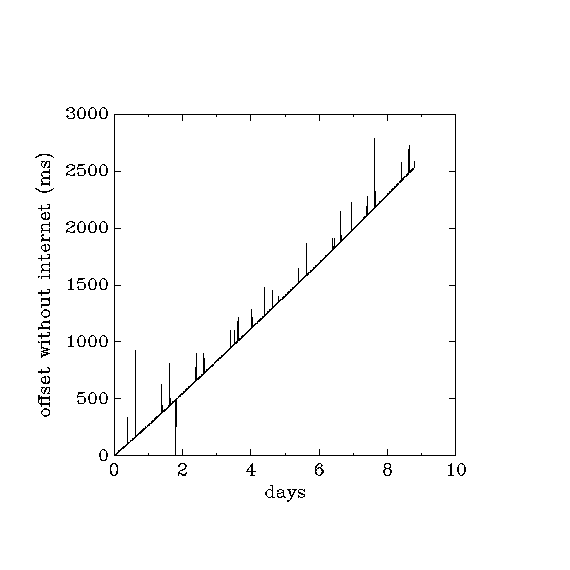

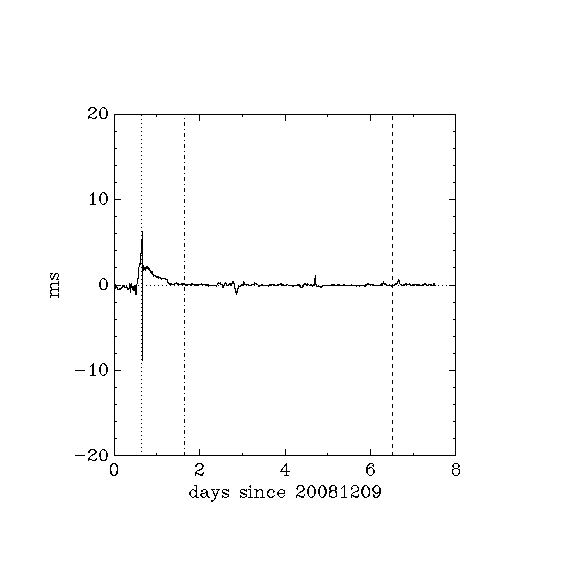
 Comment: The ntp server here is on the same LAN as the rtlinux machine, so it is reasonable that internet traffic effects have very little effect on the relative timing between the two machines. The ntp server did not have any special modifications, e.g. cron jobs and so on were not turned off. However, only 1 user was logged in from 0.65 days till the end of the period, and that user wasn't running anything except idle shells.
Comment: The ntp server here is on the same LAN as the rtlinux machine, so it is reasonable that internet traffic effects have very little effect on the relative timing between the two machines. The ntp server did not have any special modifications, e.g. cron jobs and so on were not turned off. However, only 1 user was logged in from 0.65 days till the end of the period, and that user wasn't running anything except idle shells.
Can ntp be used to keep time accurate to within 10ms ?
Initial analysis
- It seems that a default debian/etch install: aptitude install ntp gives a good default configuration that indirectly contacts a large pool of "stratum 1" ntp servers, e.g. icm.edu.pl which seems to have an atomic clock, and that the precision should be sufficient
- ignore ntp-server, ntp-simple
- ignore ntpdate - you might be able to use it usefully, but you probably do not want it - see NtpVsNtpdate
- optionally install ntp-doc
- By installing ntp, the daemon ntpd will automatically be started. Do not try to run ntpdate by hand or with cron, since it should be disabled anyway, since the daemon is running.
- There is a daily cron job installed with the daemon package (ntp), but all it does is rotate the log files (instead of logrotate :P). You can edit /etc/cron.daily/ntp in order to keep a much longer backlog of logs - the default is just the last 7 days.
- The typical polling interval of remote ntp servers appears to be about 15-20 minutes on 3 different machines.
- The absolute offsets were a little less than 10ms for the last 7 days on all 3 machines.
- The ntp algorithm in general seems to be quite intelligent, using heuristic models to overcome various real-time problems such as occasional network congestion, individual server failure, and the hardware characteristics of localhost.
- 2008.10.20 to 2008.10.28 on simulation machine: ntp_offset_20081020_20081028_bell.png:

algorithm
From ntpd/ntp_loopfilter.c (ntp-4.2.2.p4+dfsg):* This is an implementation of the clock discipline algorithm described * in UDel TR 97-4-3, as amended. It operates as an adaptive parameter, * hybrid phase/frequency-lock loop. A number of sanity checks are * included to protect against timewarps, timespikes and general mayhem. * All units are in s and s/s, unless noted otherwise.
- probably UDel TR 97-3-3 is this one: http://www.cis.udel.edu/~mills/database/reports/allan/secureb.pdf
- related algorithm discussion: http://www.cis.udel.edu/~mills/precision.html
- NTP working group: https://lists.ntp.org/mailman/listinfo/ntpwg
- IETF and RFC's: http://www.ietf.org/html.charters/ntp-charter.html
What offsets plotted above and below? What info is listed in peerstats ?
Unless otherwise noted here, these are column 5 of /etc/log/ntpstats/peerstats* in lines which have the status code 9614.- slightly old description from SUN: http://www.sun.com/blueprints/0901/NTPpt3.pdf
- page 15 states "The fifth field in the peerstat output shows estimated offset to that particular host (in seconds), which represents how far the client's clock appears to be off that of the listed server."
- From ntpd/ntp_util.c it looks like the eighth field (not mentioned in NTPpt3.pdf) is the skew.
source ntp-4.2.2.p4+dfsg
- ntpd/ntp_util.c
record_loop_stats( double offset, double freq, double jitter, double stability, int spoll ) { ... if (peerstats.fp != NULL) { fprintf(peerstats.fp, "%lu %s %s %x %.9f %.9f %.9f %.9f\n", day, ulfptoa(&now, 3), stoa(addr), status, offset, delay, dispersion, skew); fflush(peerstats.fp); } - ntpd/ntp_loopfilter.c
grep -n record_loop ntpd/ntp_loopfilter.c 245: record_loop_stats(fp_offset, drift_comp, clock_jitter, 291: record_loop_stats(fp_offset, drift_comp, clock_jitter, 755: record_loop_stats(clock_offset, drift_comp, clock_jitter,
possible parameters to play with
config files
- /etc/defaults/ntp
- Maybe add -N To the extent permitted by the operating system, run the ntpd at the highest priority. ?
- /etc/ntp.conf
- minpoll, maxpoll - increase frequency of "polling" servers?
- replace server [0123].debian.pool.ntp.org iburst by server [0123].debian.pool.ntp.org iburst minpoll 6 maxpoll 8 = 1 to 4 minutes instead of the default 1 to 17 minutes ?
- this seems to be effective - see below
- replace server [0123].debian.pool.ntp.org iburst by server [0123].debian.pool.ntp.org iburst minpoll 6 maxpoll 8 = 1 to 4 minutes instead of the default 1 to 17 minutes ?
- minpoll, maxpoll - increase frequency of "polling" servers?
source files - recompile
- include/ntp.h
- Clock filter algorithm tuning parameters ?
- Selection algorithm tuning parameters ?
- decrease: #define MINDISPERSE .005 /* min dispersion increment */ ?
maxpoll 8 in ntp.conf
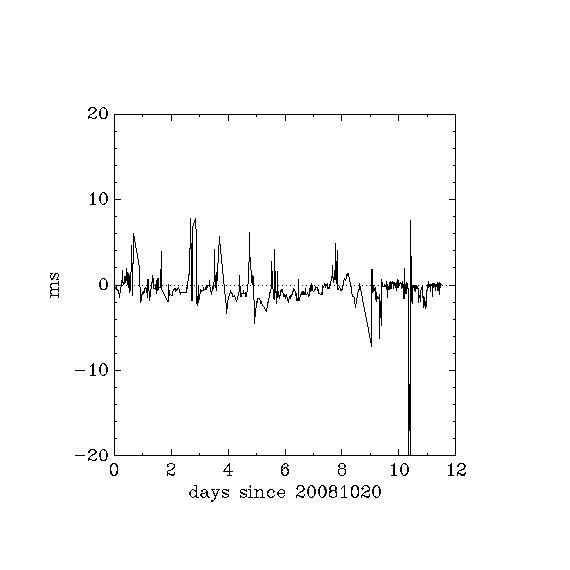
statistics on simulation machine: 8 days with maxpoll 10 and 2 days with maxpoll 8
The setting maxpoll 8 means max polling interval is, maxpoll 10 (debian/etch default) means about 16 minutes max polling interval. Two plots of the same data - offsets from the server which at that moment is chosen as the synchronisation server - with different vertical scales:
At each polling interval, several servers are contacted. A complex algorithm is used to choose among these and decide which server is most reliable/precise. In practice, the chosen server can remain stable for many hours or days.
Statistics of these offsets in units of 300 km (a.k.a. 1 ms):
| maxpoll | approx. test duration (d) | min | max | mean | s.d. | rms |
|---|---|---|---|---|---|---|
| 10 | 8 | -4.51 | 7.76 | -0.42 | 1.55 | 1.61 |
| 8 | 4 | -21.48 | 7.59 | -0.54 | 2.24 | 2.31 |
| 8 exclude 2.4h spike | 3.9 | -3.48 | 1.93 | -0.28 | 0.59 | 0.65 |
- In the interval 8.5 to 9.4 days, some experimentation was going on, so this period should be ignored.
- At about 13.9 days, an intensive ssh session through that machine to another machine was taking place. Speculation: was this intense enough network and/or cpu usage to be responsible for the small negative spike of about 3ms ?
100 machine-days: statistics on 5 machines * 20 days with maxpoll 8
- a_ntp_offset_20081030_20081120.png:
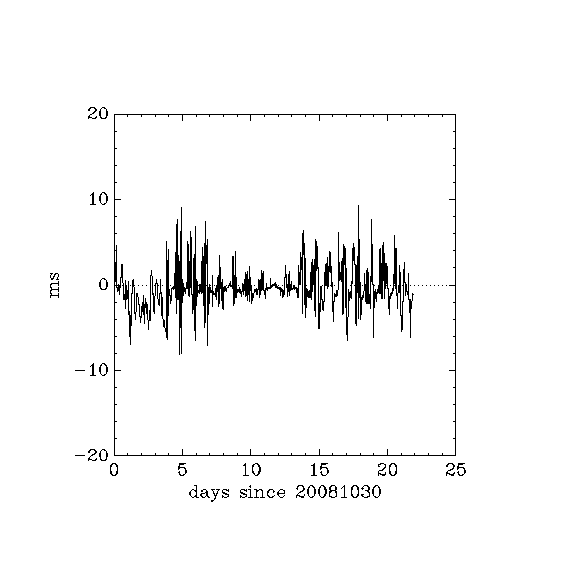
- a: 5 different local users, webserver regularly bashed by google, no reboots
- b_ntp_offset_20081030_20081120.png:
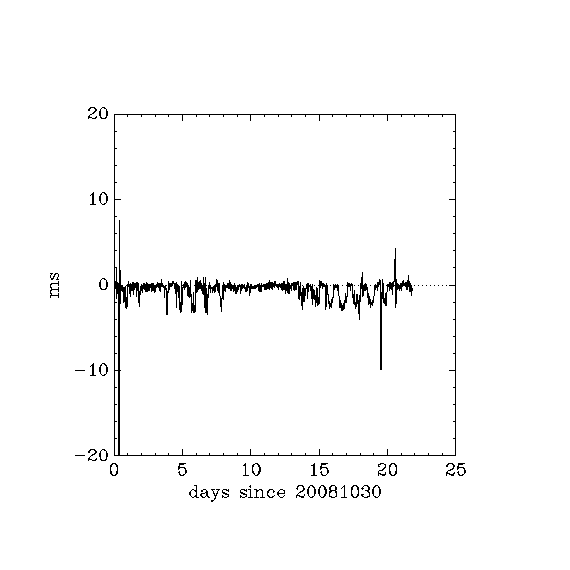
- b: 1 user
- c_ntp_offset_20081030_20081120.png:
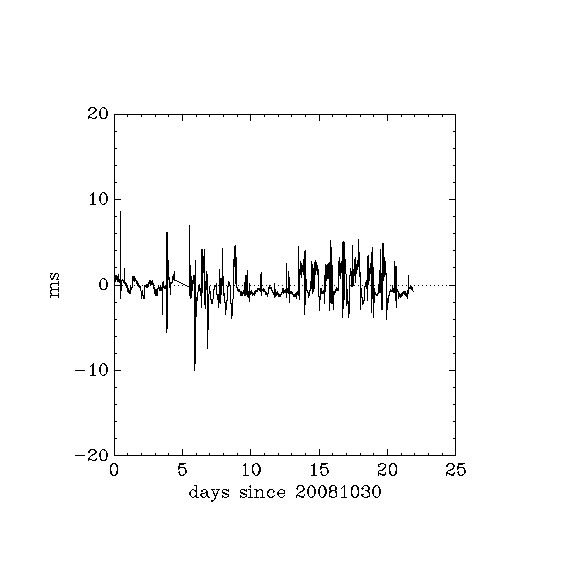
- c: 1 user, reboot 4 Nov = day 5 after 26 hours down time - 7ms spike 4 minutes after end of reboot, down to 1.2ms 2 minutes later
- p_ntp_offset_20081030_20081120_96b4.png (both 9614 and 9624 status codes):
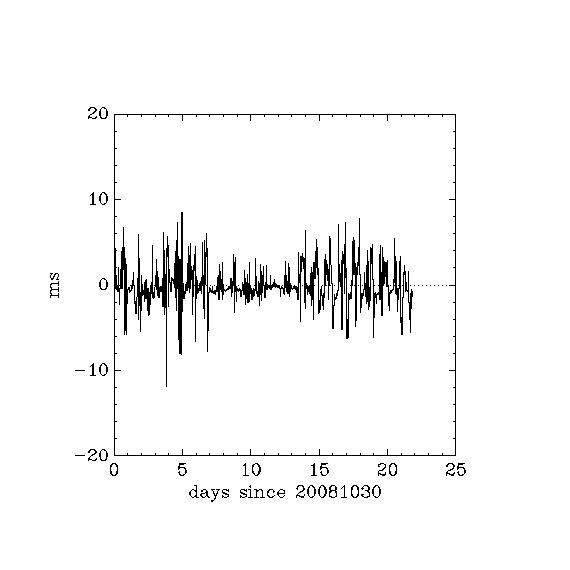
- p: 8 local users, webserver mildly used by google + world, no reboots
- h_ntp_offset_20081030_20081120.png:
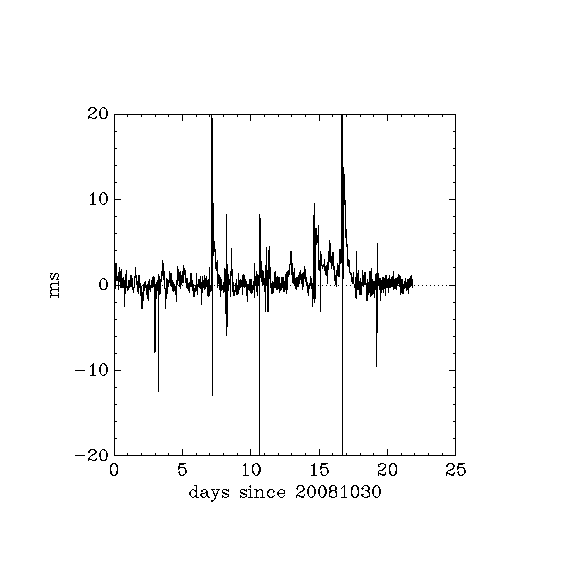
- h: (slow internet connection) 2 local users, reboot for 2 minutes @6 Nov = day 7
what happens when internet access is lost?
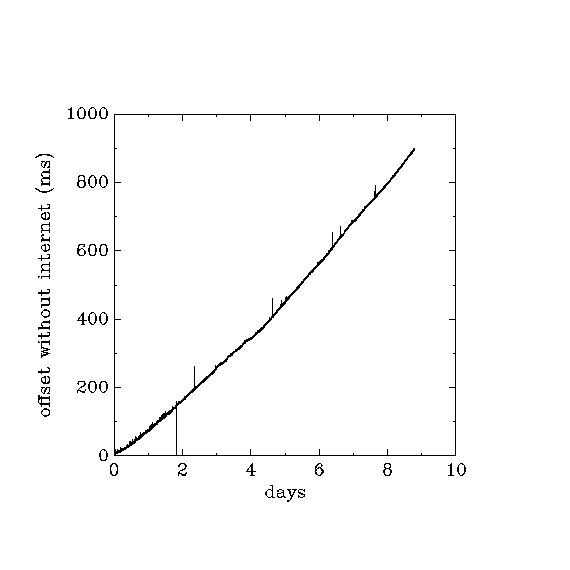
By definition, ntpd cannot expect to do much expect for assuming that the general correction (drift?) calculated during the period with internet access remains valid when internet access is cut off. A test during about 9 days on 3 machines with udp port 123 blocked (to simulate loss of internet access), using ntpq to check the current time from machine b on the same LAN each 5 minutes, and bracketting the ntpq queries with a local date enquiry, gives approximately linear growth of errors at average rates of:- a : -12.198 ms/hour
- c : -4.2500 ms/hour
- p : -0.2642 ms/hour
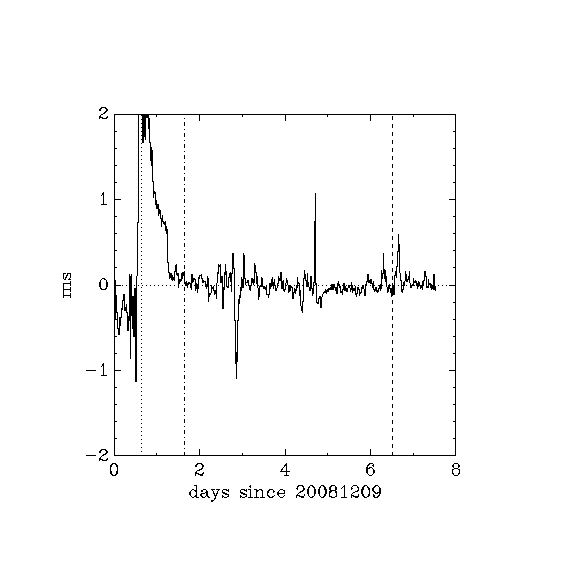
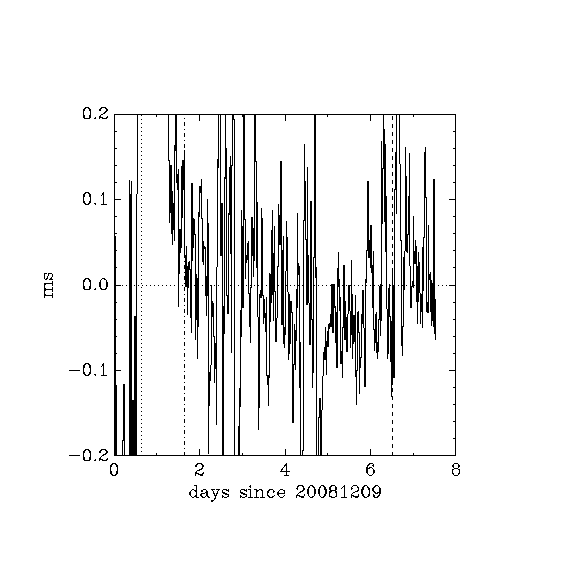
Does this 10ms limit remain valid if ntpd is run from "linux" and rtlinux is running at the same time?
Method
- machine b running rtlinux chooses machine c (on LAN) as its only ntp server, i.e. it ignores the standard debian pool of servers.
- testing with simulated telescope tracking, dT \sim 120ms on simulator
- from 0.65 days to 1.65 days,
- from 6.5 days to end,
- stationary, dT \sim 70ms on simulator
- 1.65 days to 6.5 days
- (the initial 0 to 0.65 days should be ignored)
- Uwaga! the three diagrams show the same info, one on a +-20ms scale, one on a +-2ms scale, one on a +-0.2ms scale
Comment: The ntp server here is on the same LAN as the rtlinux machine, so it is reasonable that internet traffic effects have very little effect on the relative timing between the two machines. The ntp server did not have any special modifications, e.g. cron jobs and so on were not turned off. However, only 1 user was logged in from 0.65 days till the end of the period, and that user wasn't running anything except idle shells.
TODO
other
- debate including main ntp author, David Mills of Uni of Delaware, USA: http://fixunix.com/ntp/67707-ntpd-pll-clock-overshoot.html
DONE
Check that all is OK after aptitude update/upgrade
- Seems fine after upgrade.
Does this 10ms limit remain valid during intense simulated telescope usage?
- Monitoring on 5 different machines started. By early Dec 2008 we should have 5 machine-months of peerstats files.
- See above for 100 machine-days.
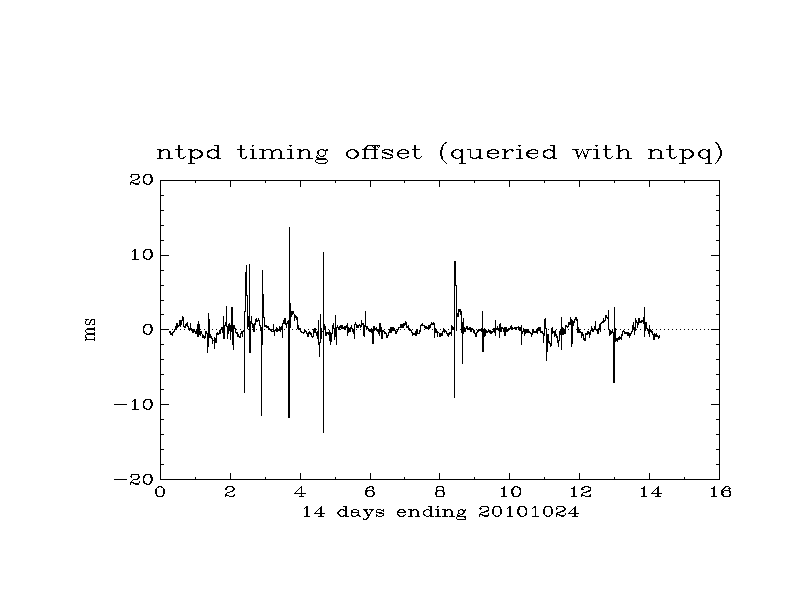
October 2010
- double check rt4 ntpd accuracy - rms offset over two weeks to 2010-10-24 is 1.256 ms
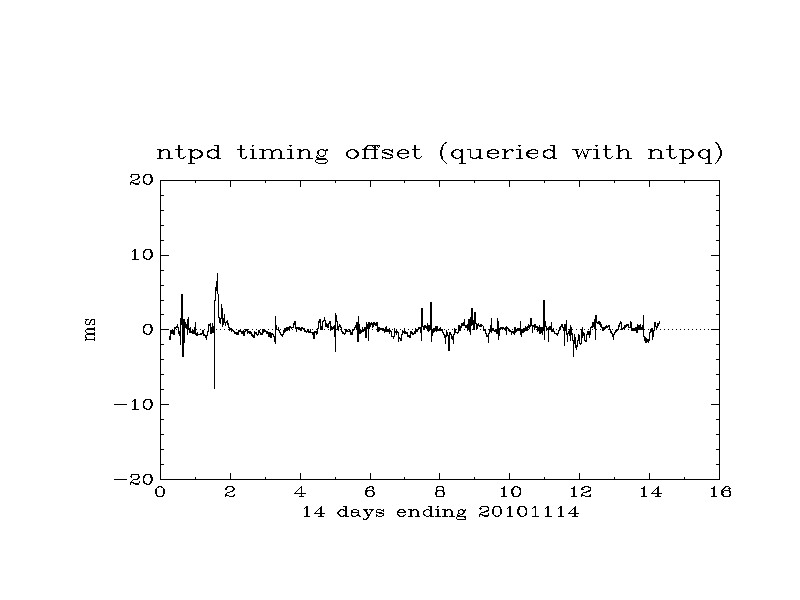
- another - rms offset over two weeks to 2010-11-14 is 0.872 ms


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
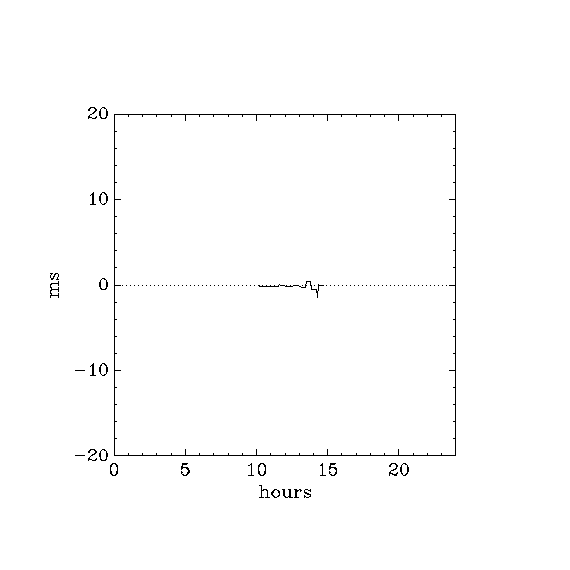{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r15 < r14 < r13 < r12 | Backlinks | View wiki text | More topic actions
Topic revision: r15 - 18 Nov 2010, BoudRoukema
Ideas, requests, problems regarding Foswiki? Send feedback